ldEngine: Drawing One Million Quads with OpenGL
Experimenting with persistently mapped buffers

Introduction
The idea for building my own renderer came from the fact that I’ve started creating my own engine. It’s a very simple and it’s not even close to what popular engines like UE4 or Unity can do but it serves the purpose I created it for. Building 2D games.
I’ve tried designing my engine giving space for future optimizations trying to avoid the always famous quote of Donald Knuth: “Premature optimization is the root of all evil…“. Which I feel is used many times in the wrong context.
One of the first important points I wanted to approach was having a flexible and powerful renderer. Even though is 2D I still wanted to be able to push vertices as fast as possible.
For this post I won’t show exactly how I wrote my renderer because of multiple engine dependencies but I’ll show some of the core features using common libraries like SDL2, GLEW and just pure OpenGL. The source code will be available at the bottom of the post.
The Naive Renderer
The first approach was one I would consider naive. Even though I did commmon techniques like batching it still fell into the “naive” realm for me. It was flexible and easy to use but I couldn’t push as many vertices as I wanted.
The shaders I wrote for this demo are very simple and they won’t change during the whole post. I’ll just define the vertex position and color attributes (in), orthographic view matrix and varying (out) variable to pass the current vertex color to the fragment shader.
Vertex Shader
#version 120
attribute vec2 inVertexPos;
attribute vec4 inVertexCol;
varying vec4 outVertexCol;
uniform mat4 orthoView;
void main()
{
gl_Position = orthoView * vec4(inVertexPos, 1.0, 1.0);
outVertexCol = inVertexCol;
}Fragment Shader
#version 120
varying vec4 outVertexCol;
void main()
{
gl_FragColor = outVertexCol;
}In this naive approach the generation and allocation of buffers would be really simple and kind of standard. First I would declare a couple of variables.
float* pVertexPosBufferData;
float* pVertexColBufferData;
float* pVertexPosCurrent;
float* pVertexColCurrent;
GLuint vertexPosVBO;
GLuint vertexColVBO;The first 2 variables represent the preallocated memory buffer I will use to store vertex positions and vertex colors. The next 2 will represent the current address to which I would write my data. The last 2 are just GL handles for VBOs.
On my engine I would actually use a custom allocator to handle the first 4 variables. I would highly recommend using the same approach, also because you can implment memory debugging and tracking capabilities to that allocator. In this case I won’t bother with that and do straightforward pointer arithmetic.
The allocation of the buffers on GPU would be done with glBufferData and I would allocate the same size of the buffer on the heap to store my vertex data before flushing it.
static const size_t VertexPosBufferSize = SPRITE_COUNT * (sizeof(float) * 12);
static const size_t VertexColBufferSize = SPRITE_COUNT * (sizeof(float) * 24);
// Allocate space for our vertex data
pVertexPosBufferData = (float*)malloc(VertexPosBufferSize);
pVertexColBufferData = (float*)malloc(VertexColBufferSize);
pVertexPosCurrent = pVertexPosBufferData;
pVertexColCurrent = pVertexColBufferData;
// Bind our buffer
glBindBuffer(GL_ARRAY_BUFFER, vertexPosVBO);
// Allocate space for our buffer
glBufferData(GL_ARRAY_BUFFER, VertexPosBufferSize, NULL, GL_DYNAMIC_DRAW);
glEnableVertexAttribArray(locVertexPos);
// Set the format and location of our attribute "inVertexPos". In this case it's a vec2
glVertexAttribPointer(locVertexPos, 2, GL_FLOAT, GL_FALSE, 0, NULL);
// Do the same for our vertex color VBO.
glBindBuffer(GL_ARRAY_BUFFER, vertexColVBO);
glBufferData(GL_ARRAY_BUFFER, VertexColBufferSize, NULL, GL_DYNAMIC_DRAW);
glEnableVertexAttribArray(locVertexCol);
glVertexAttribPointer(locVertexCol, 4, GL_FLOAT, GL_FALSE, 0, NULL);You can see in the first two lines I define the size of my vertex buffers. You can notice that I multiply sizeof(float) * 12 for vertex position buffer and sizeof(float) * 24 for vertex color buffer. This is because each sprite is formed by 2 triangles which is equal to 6 vertices. For vertex position attribute we use a vec2 and for vertex color attribute we use a vec4, this means each quad or sprite uses 12 float elements for vertex position and 24 float elements for vertex color.
When I started writing my renderer I wanted to have a very simple API to deal with. I’ve worked a lot with Monkey-X and I really like the mojo API so I went with a similar one. For this example I’ll just write a function to draw a rectangle which I’ll call drawRect, a function to set the current draw color which I’ll call setColor and a function to “flush” the data and push it to the GPU which I’ll call flush.
void drawRect(float x, float y, float width, float height);
void setColor(float red, float green, float blue, float alpha);
void flush();The function drawRect only writes the vertex data to the heap allocated buffer.
void drawRect(float x, float y, float width, float height)
{
// Start writing quad data into
// pVertexPosBufferData and pVertexColBufferData
...
// End writing quad data.
// We offset our current pointers to the
// next available location. Kind of like a stack.
pVertexPosCurrent = (float*)((char*)pVertexPosCurrent + (sizeof(float) * 12));
pVertexColCurrent = (float*)((char*)pVertexColCurrent + (sizeof(float) * 24));
// We increment the quad count so we
// add this quad to the current draw call batch.
++quadCount;
}The implmentation of flush is also very simple and straightforward. We bind our buffers and do a memcpy using glBufferSubData. This will update the buffer object’s data store and make it available for rendering. We finally call glDrawArrays and render our geometry on the current frame buffer.
void flush()
{
// Update buffer's store data
glBindBuffer(GL_ARRAY_BUFFER, vertexPosVBO);
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(float) * quadCount * vertPerQuad * 2, pVertexPosBufferData);
glBindBuffer(GL_ARRAY_BUFFER, vertexColVBO);
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(float) * quadCount * vertPerQuad * 4, pVertexColBufferData);
// Render geometry
glDrawArrays(GL_TRIANGLES, 0, (GLsizei)(quadCount * vertPerQuad));
// Reset client data
quadCount = 0;
pVertexPosCurrent = pVertexPosBufferData;
pVertexColCurrent = pVertexColBufferData;
}
Running Test: glBufferSubData
With all the rendering part setup we are finally able to draw some stuff on screen. So what I do is just create a simple structure called Particle that contains position, velocity and color information.
struct Particle
{
float positionX;
float positionY;
float velocityX;
float velocityY;
float colorR;
float colorG;
float colorB;
};We initialize it and run our simulation.
while (run)
{
glClear(GL_COLOR_BUFFER_BIT);
updateParticles(pParticles);
renderParticles(pParticles);
flush();
}What renderParticles does is basically iterate through each particle pushing the quad and color information to our heap allocated buffers. Something like this:
void renderParticles(struct Particle* pParticles)
{
for (size_t index = 0; index < SPRITE_COUNT; ++index)
{
struct Particle* pParticle = pParticles[index];
setColor(pParticle->colorR, pParticle->colorG, pParticle->colorB, 1.0f);
drawRect(pParticle->positionX, pParticle->positionY, 1.0f, 1.0f);
}
}The results of this test can be seen in this image:
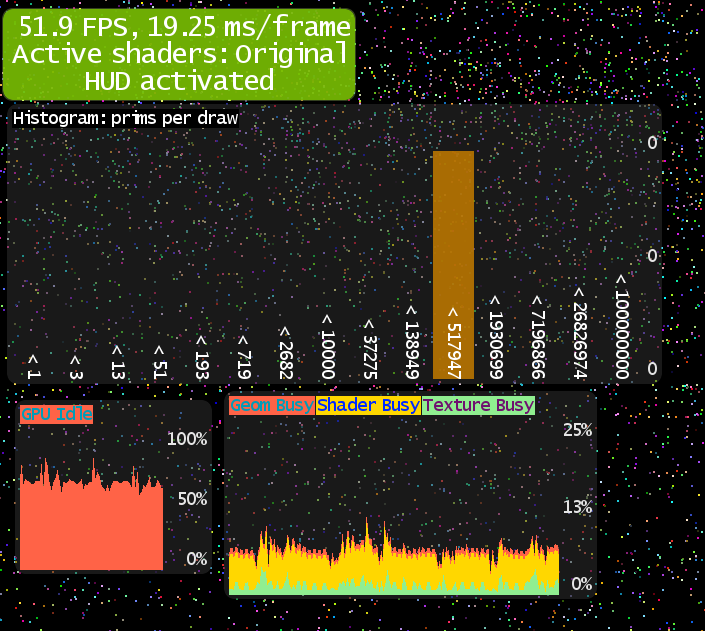
On my machine I was able to render about 160.000 individual quads (about 960.000 vertices) before getting a drop on my FPS. This is still pretty good but not what I was looking for.
I want to draw ONE MILLION sprites!
Now What? Let’s Stream Geometry
In this new approach we will do Buffer Object Streaming with Persistent Mapping of Buffers. Buffer Object Streaming consist of modifying a buffer object with new data while it’s being used. Once you’re done writting to the buffer you do a draw call which starts a “use” cycle on the GPU. Persistent Mapping of Buffers consists of mapping a region of our GPU memory with the client address space only once. It’s persistent because we don’t have to map and unmap the region every time we want to push data to the GPU. We only unmap this region when we want to delete the buffer. So what is the benefit compared to the previous approach? Well, We can use our own custom allocator to manage that memory as we want. We don’t need to call malloc to keep a copy of our vertex data on heap. Once we are done doing our stuff we just call glDrawArrays. This means no more binding buffers and updating using glBindBuffer, glBufferSubData and no more mapping and unmapping, which is terrible for performance. With all this in mind we can implement a flush function that looks a lot cleaner, just a single glDrawArrays.
void flush()
{
// Render geometry
glDrawArrays(GL_TRIANGLES, 0, (GLsizei)(quadCount * vertPerQuad));
// Reset client data
quadCount = 0;
pVertexPosCurrent = pVertexPosBufferData;
pVertexColCurrent = pVertexColBufferData;
}To use this approach we need a driver with the following GL extensions:
ARB_buffer_storage Requires OpenGL 4.3+
ARB_map_buffer_range Requires OpenGL 2.1+
If we are working with OpenGL for Embedded Systems (ES), the extensions are:
EXT_buffer_storage Requires OpenGL ES 3.1+
EXT_map_buffer_range Requires OpenGL ES 2.0+
So now that we are going with a Buffer Object Streaming with a Persistent Buffer Mapping we need to change the VBO allocation routine. Our previous VBO allocation looked like this:
...
// Bind our buffer
glBindBuffer(GL_ARRAY_BUFFER, bufferHandle);
// Allocate space for our buffer
glBufferData(GL_ARRAY_BUFFER, bufferSize, NULL, GL_DYNAMIC_DRAW);
...Now it should look like this:
// Memory mapping flags
GLbitfield fMap = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
// Buffer creation flags
GLbitfield fCreate = fMap | GL_DYNAMIC_STORAGE_BIT;
glBindBuffer(GL_ARRAY_BUFFER, vertexPosVBO);
// Initialize and allocate our buffer object
glBufferStorage(GL_ARRAY_BUFFER, vpSize, nullptr, fCreate);
glEnableVertexAttribArray(locVertexPos);
glVertexAttribPointer(locVertexPos, 2, GL_FLOAT, GL_FALSE, 0, nullptr);
// We map the VBO GPU address to our client address space.
pVertexPosBufferData = (float*)glMapBufferRange(GL_ARRAY_BUFFER, 0, vpSize, fMap);
pVertexPosCurrent = pVertexPosBufferData;
// Do the same for vertex color VBO
glBindBuffer(GL_ARRAY_BUFFER, vertexColVBO);
glBufferStorage(GL_ARRAY_BUFFER, vcSize, nullptr, fCreate);
glEnableVertexAttribArray(locVertexCol);
glVertexAttribPointer(locVertexCol, 4, GL_FLOAT, GL_FALSE, 0, nullptr);
pVertexColBufferData = (float*)glMapBufferRange(GL_ARRAY_BUFFER, 0, vcSize, fMap);
pVertexColCurrent = pVertexColBufferData;fMap will enable persistent mapping, which will allow us to write to the returned address space even when it’s being used by the GPU.
fCreate will allow us to dynamically update the buffer’s data store.
Running Test: Buffer Object Streaming with Persistent Mapping of Buffers
We are running the same test we ran previously but with different VBO allocation and flush function.
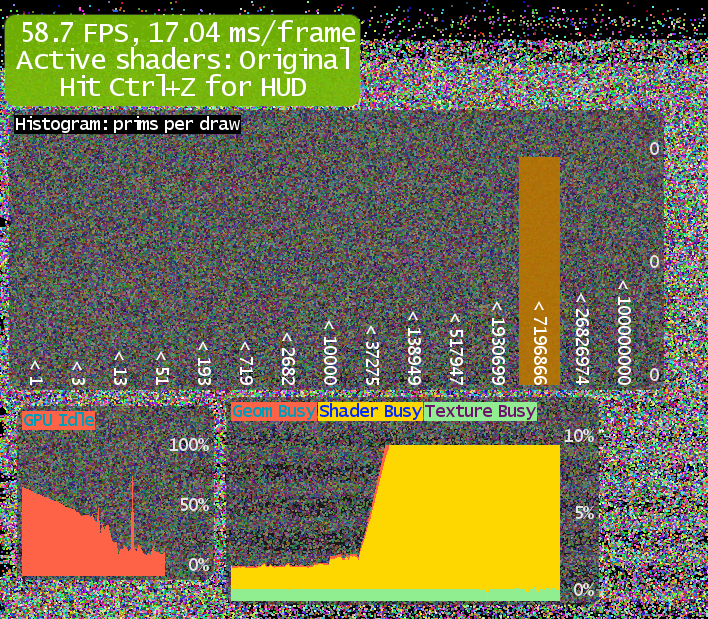
The performance boost is undeniable. We went from 160.000 (960.000 vertices) quads to 1.000.000 (6.000.000 vertices) quads. That’s bit more than 6 times more quads. All of this is running at 60 FPS on my machine.
Here you can see a small comparison between both approaches:
Conclusion
This was defintely a good approach for PC. If the minimum spec needed to run your game supports OpenGL 4.3+ then you’ll be able to get a nice performance boost. Sadly it still not available in popular mobile devices like Apple’s. There is a couple of devices that run Android/Linux/Windows that support OpenGL ES 3.1, you can see a list here. It’ll all depend on your hardware and driver specs. We can always fallback to our glBufferSubData technique if it’s not supported but it’s nice to be prepared anyways.
Links
- Demo Source Code: https://github.com/bitnenfer/GLSpriteRenderDemo
- Buffer Object Streaming - OpenGL Wiki: https://www.opengl.org/wiki/Buffer_Object_Streaming
- OpenGL Efficiency: AZDO https://www.khronos.org/assets/uploads/developers/library/2014-gdc/Khronos-OpenGL-Efficiency-GDC-Mar14.pdf